
前回の記事
ファイル選択画面表示
さっそくOnBnClickedButtonInput内に読込処理を作ります。
まずは、テキストファイルを読み込むためファイル選択画面を出さなければいけません。
読込処理はいったん置いといて、その画面を出す処理を作成します。
void CTextInputOutputDlg::OnBnClickedButtonInput()
{
// ここはテキスト読込処理
CString strTitle = _T("テキスト読込処理タイトル");
static char BASED_CODE szFilter[] = "テキストドキュメント|*.txt|";
// CFileDialog インスタンスの作成
CFileDialog* dlgFile = new CFileDialog(TRUE, NULL, NULL, OFN_HIDEREADONLY | OFN_OVERWRITEPROMPT, szFilter);
dlgFile->m_ofn.lpstrTitle = strTitle; // タイトル設定
// ファイルダイアログの表示
INT_PTR iRetFileDlg = dlgFile->DoModal();
if (iRetFileDlg == IDOK)
{
// OKボタンが押下された
}
else
{
// キャンセルボタンが押下された
}
}
これでいったんビルドしてexeを開いてみます。

テキスト読込ボタンを押下すると

選択画面が出てきました。
補足
上記コードをコピーして、この行でエラーが出てしまうことがあるかもしれません。
CFileDialog* dlgFile = new CFileDialog(TRUE, NULL, NULL, OFN_HIDEREADONLY | OFN_OVERWRITEPROMPT, szFilter);
この場合、プロジェクトのプロパティを選択します。
詳細→文字セットから、
「マルチバイト文字セットを使用する」を選択し、適用してください。
エラーが消えると思います。

読込処理
次いで、読込処理を書いていきます。
追加する部分はif (iRetFileDlg == IDOK)の場合。
elseに行くとキャンセルの場合なので、そこはセットする必要ないですよね。
if文の中だけ追記します。
if (iRetFileDlg == IDOK)
{
// 開くボタンが押下された
CString strPath = dlgFile->GetPathName(); //ファイルのパス
CFile file;
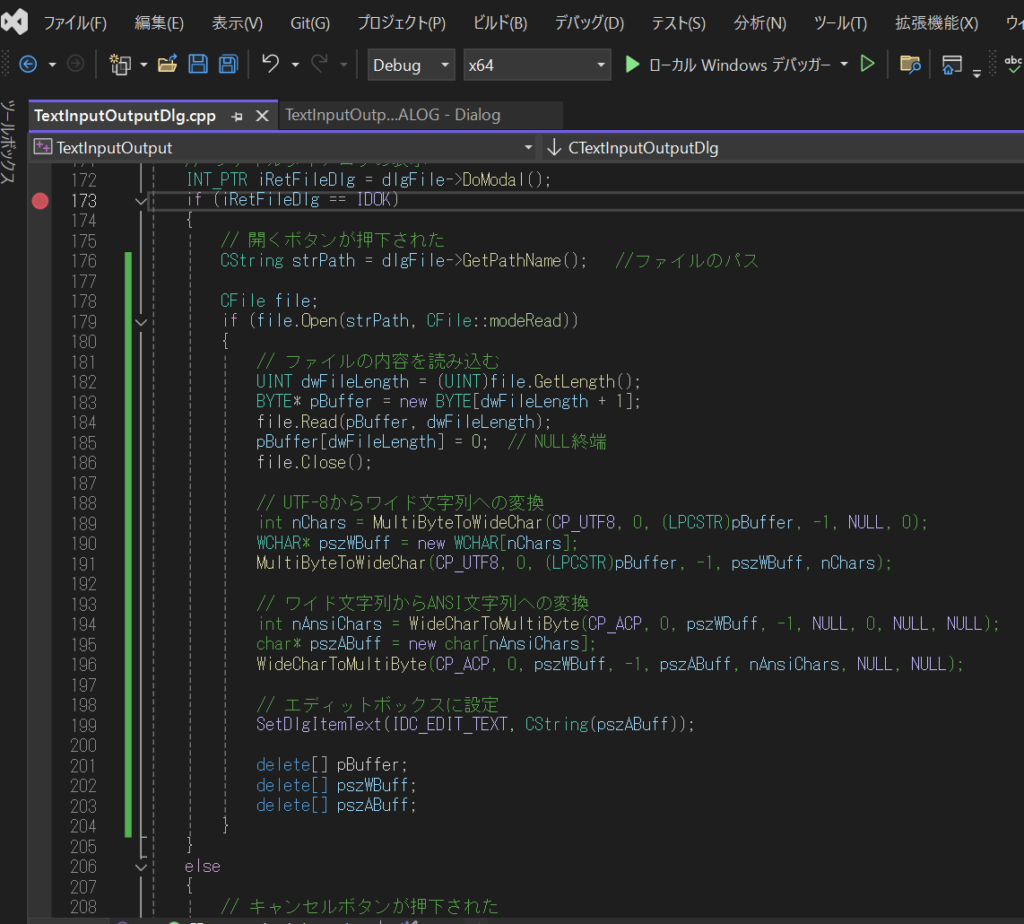
if (file.Open(strPath, CFile::modeRead))
{
// ファイルの内容を読み込む
UINT dwFileLength = (UINT)file.GetLength();
BYTE* pBuffer = new BYTE[dwFileLength + 1];
file.Read(pBuffer, dwFileLength);
pBuffer[dwFileLength] = 0; // NULL終端
file.Close();
// UTF-8からワイド文字列への変換
int nChars = MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)pBuffer, -1, NULL, 0);
WCHAR* pszWBuff = new WCHAR[nChars];
MultiByteToWideChar(CP_UTF8, 0, (LPCSTR)pBuffer, -1, pszWBuff, nChars);
// ワイド文字列からANSI文字列への変換
int nAnsiChars = WideCharToMultiByte(CP_ACP, 0, pszWBuff, -1, NULL, 0, NULL, NULL);
char* pszABuff = new char[nAnsiChars];
WideCharToMultiByte(CP_ACP, 0, pszWBuff, -1, pszABuff, nAnsiChars, NULL, NULL);
// エディットボックスに設定
SetDlgItemText(IDC_EDIT_TEXT, CString(pszABuff));
delete[] pBuffer;
delete[] pszWBuff;
delete[] pszABuff;
}
}
else
{
// キャンセルボタンが押下された
}
これをビルドしします。
デスクトップ上のフォルダ内に、こんなテキストファイルを用意しました。

こいつを読み込んでみます。

さて、開くボタンを押してみます
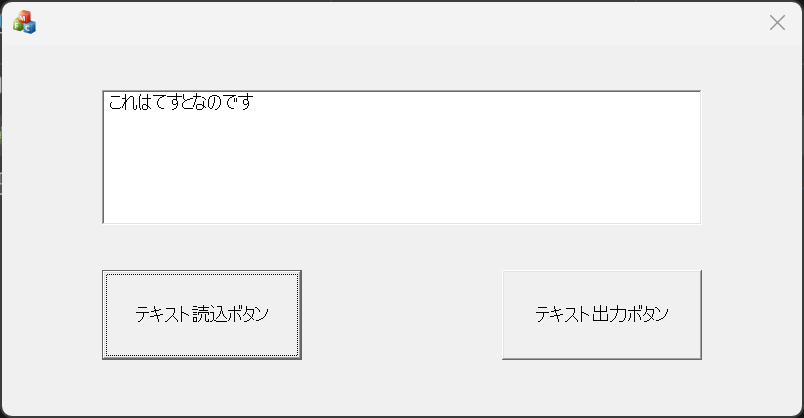
良さげです。
少しだけコードの補足を。
文字化け対処のため、後半に変換処理を行っています。
マルチバイト文字セットを使用している場合、
ファイルのエンコーディングによっては文字化けが発生していしまいます。
(実際、UTF-8のファイルを上記変換処理を行わず普通に読み込もうとした場合、
見事に文字化けが出てしまいました↓↓↓)

まぁ、テキストファイルをANSIにして保存すればいいのですが、そういう問題ではなくて。
対策として、UTF-8エンコードされたファイルを読み込んで、
システムのデフォルトANSIエンコーディングに変換してします。
手順としては
- ファイル全体をバイト配列として読み込む
- バイト配列をUTF-8からUnicodeへ変換
- 最後にシステムのデフォルトANSIエンコーディングへ変換
となっています。
変換後は、読み取った値をエディットボックスにセットします。
終わりに
今回は読込処理でした。
実は文字化けのところ、少し苦労しました。
昔業務で似たような処理を追加したのですが、
その時は全然文字化け発生しなかったので。
設定か、既存の処理が何か働いていたのかわかりませんが。
次回(多分)最終回、テキスト出力です。

コメント